

| In short You use the LLM once, at generation time, to author the tests. What you keep is a deterministic test suite that runs with no model in the loop: no tokens at runtime, nothing decided mid-run, the same result every time. |
Lots of QA teams are exploring AI-assisted testing right now. Many of the solutions on the market involve the LLM at every step: generating the tests, making decisions during the run, adjusting assertions on the fly. It sounds appealing until you think about what it costs. If an LLM is deciding what happens on each run, your tests are non-deterministic. You get false positives, false negatives, and hallucinated logic, and you can never be sure a test passed or failed for the right reason.
We have released the AltTester® CLI and a new version of the AI Extension that includes a set of AI skills, alongside the existing MCP server. But we want to be direct about how we think about this differently. The workflow we recommend uses the LLM for the authoring phase, under your review, and then steps out of the loop entirely. The suite it generates runs deterministically from then on: no tokens at runtime, no decisions made by a model mid-test, the same result every time.
This post walks through that workflow using a real example, a co-op cooking game, from initial exploration to a runnable Robot Framework suite.
What makes it possible: the CLI and the MCP server
AltTester® already lets you test Unity or Unreal games on any target platform. You add the SDK, build as usual, and that instrumented build exposes every object inside the game. AltTester® Desktop connects to the build over a secure WebSocket, locally or over the network, and gives you an inspector and a recorder.
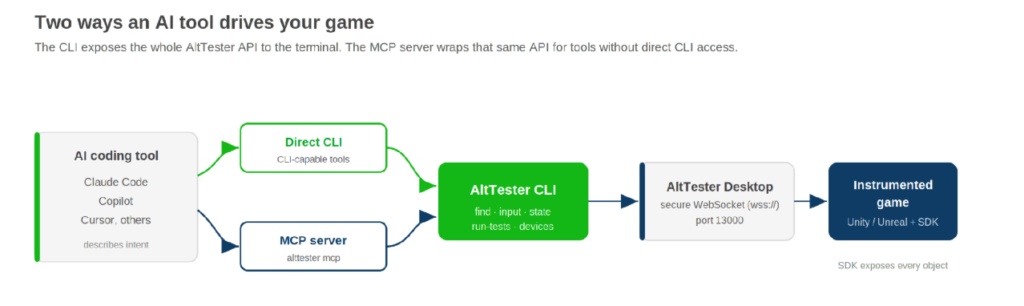
The two components that bring AI into this workflow are the CLI and the MCP server.
The CLI exposes the entire AltTester® API from the terminal. Finding objects, simulating inputs, reading and writing game state, running tests, and managing devices each become a command an agent can call, chain, and reason about. An AI tool does not need to understand a graphical interface. Give it a structured, scriptable interface, and it can work with it directly. Any CLI-capable tool, Claude Code among them, can drive the game this way.
The MCP server covers everything else. For tools that do not support direct CLI access, you run alttester mcp and connect any MCP-compatible IDE. It wraps the same API over the Model Context Protocol, so the tool gets the same capabilities without a shell. The CLI and the MCP server are two doors into the same room.
A model that can call commands is not the same as a model that knows how to test. The gap between the two is what the skills close. One command, alttester install-skills, installs an AltTester® skill into your AI coding assistant, so you are not re-explaining the same context every session. You choose between two skills.
| Skill | When to use it |
|---|---|
| Robot | For teams that do not have a test framework yet and would rather not write test code by hand. The AI guides you through planning, generating, running, and recording tests with Robot Framework, whose keyword-driven syntax reads close to natural language. |
| Helper | For teams that already have tests in place. It works across C#, Python, Java, and others, helping with debugging failures, healing broken tests, and writing new tests that match the conventions you already use. |
For the cooking game, I installed the Robot skill, because the point is to start from scratch and end up with a runnable suite without writing code by hand.
The walkthrough
The setup is deliberately ordinary. On the left, an instrumented co-op cooking game. As documentation, the kind of thing most teams already have: a short game overview plus the existing smoke and regression cases. The editor is Visual Studio Code with its integrated terminal.
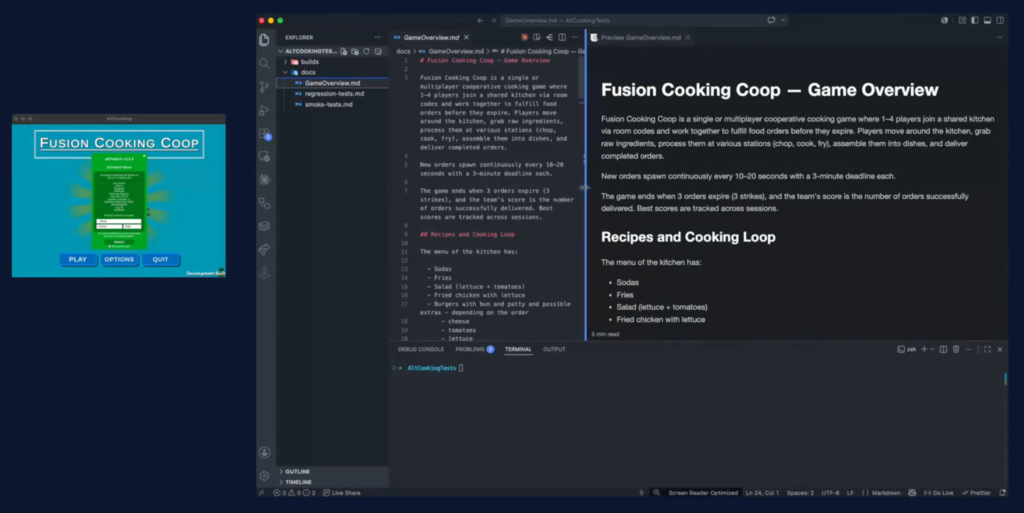
I started Claude Opus 4.8, with its 1 million token context, and gave it a plain prompt. I asked it to read the available documentation and automate the first two tests from the smoke set, and I told it the game was already running and connected to AltTester® Desktop. Here is what it did, in order.
- It detected the skill and used it. It connected to the game and interacted directly: pressing buttons, naming the kitchen, setting a chef nickname (smoke chef), and finding the input controller. That is the first two smoke tests, end-to-end, driven from the terminal.
- It worked out how to reset to a known state. This is the part a junior tester often misses. The model recognised that each test has to start from the same place to be repeatable, so it returned the game to the main menu before laying anything else out. Repeatability was built into the plan, not bolted on after.
- It produced a plan and a locator reference. It laid out the two smoke tests as the exact steps from our test cases, and it separately built a technical reference of the locators it had found, because it knew it would need them later.
- It flagged discrepancies between my spec and the game. It noticed places where my test cases did not match how the game actually behaves. That is fair, my spec was a little generic. I read the discrepancies, accepted them, and approved the plan. This is the human-in-the-loop moment, and it is a real signal, not a formality.
- It generated the suite in Robot Framework. The output uses a three-layer structure and reads almost like the smoke cases themselves, which keeps the generated tests legible rather than opaque.
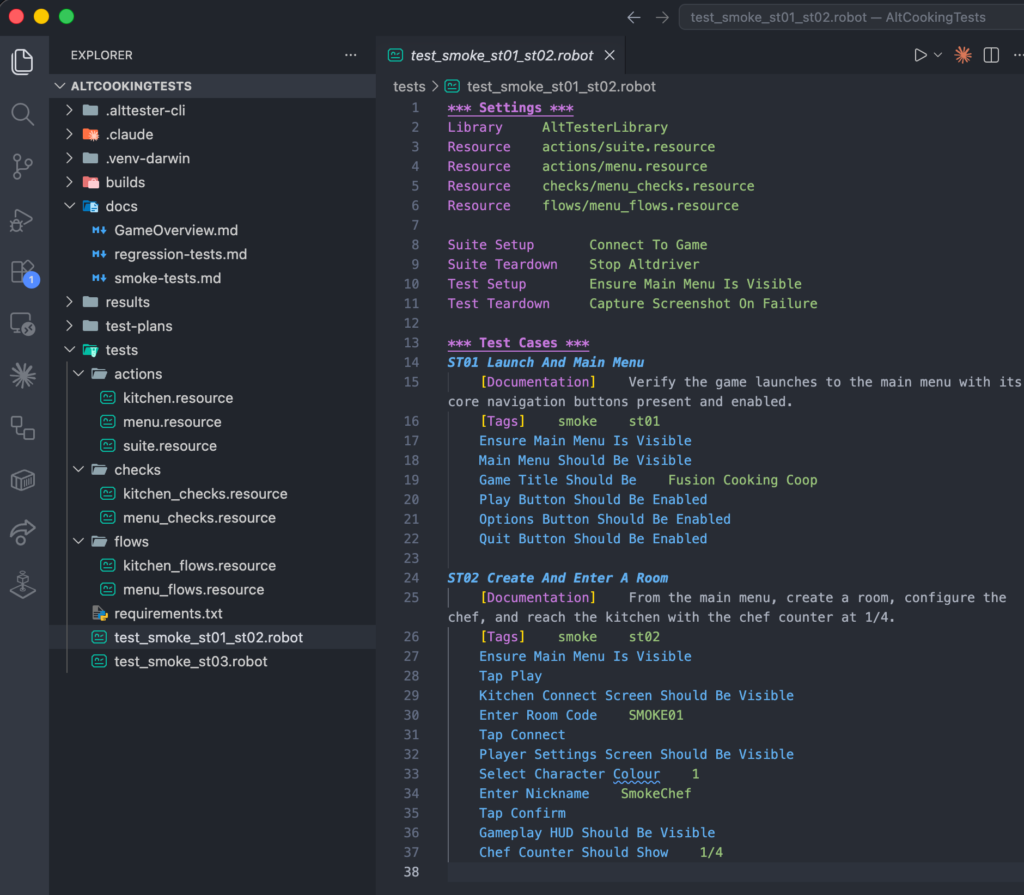
Then I ran it with alttester run-tests, and watched it execute live in the game. At the end, I got a dashboard report: every step green, every test passed. That is the test now, and I can run it again and again with identical behaviour.
The reframe: generation time versus runtime

This is the distinction that matters. The expensive, non-deterministic thing, the model reasoning about your game, happens once, under your review, to produce the cheap, deterministic thing, the suite. You are not renting an AI to re-run your smoke tests every night. You are using it to write them, once.
| The cost is a one-time cost The whole generation session used about 9% of the context. The tests it produced run for free from then on, because no model is involved when they execute. |
How the suite is organised

The Robot skill organises tests into three layers. Actions are low-level interactions, checks are assertions, and flows are multi-step scenarios that build on the other two. Robot Framework runs on Python and reads close to natural language, which keeps the generated tests legible and easy to extend by hand later.
Where the human stays in the loop
I don’t want to oversell this: the AI does not write your tests so you can stop thinking. That is not what happened, and it is not what you want. The model did the laborious work well: discovering locators, scaffolding the project, structuring the suite, and catching that my spec did not match the build. The judgement calls stayed with me. I reviewed the plan, I decided which discrepancies to accept, and I approved before any code was generated.
That division of labour is the right one. The mechanical work goes to the model. The decisions about what is worth testing and what is correct remain with the tester.
What is next: agentic mode
Everything above is the generate-then-run pattern, where the model is gone by the time the tests execute. The same CLI and MCP tools can also be used in agentic mode, where a model stays in the loop throughout the run and decides the next step as it goes. That is a different trade-off with different uses, and it deserves its own treatment. We will cover it in a follow-up.
Try it
The CLI and the AI Extension ship with AltTester® Desktop 2.3.2, and the AI Extension is currently in beta, so feedback is genuinely useful right now.
- Release notes and feature overview: AltTester® CLI release post
- Full command reference and AI Extension setup: AltTester® CLI and AI Extension docs
- The demo this post is based on: watch on YouTube
If you try it, tell us what worked and what did not, on Discord or at support@alttester.com.